|
|

|

|
| e-Pub |
Section: New Results
Unsupervised Metric Learning for Multi-shot Person Re-identification
Participants : Furqan Khan, François Brémond.
keywords: re-identification, long term visual tracking, metric learning, unsupervised labeling
Automatic label generation for metric learning
Appearance based person re-identification is a challenging task, specially due to difficulty in capturing high intra-person appearance variance across cameras when inter-person similarity is also high. Metric learning is often used to address deficiency of low-level features by learning view specific re-identification models. The models are often acquired using a supervised algorithm. This is not practical for real-world surveillance systems because annotation effort is view dependent. Therefore, everytime a camera is replaced or added, a significant amount of data has to be annotated again. We propose a strategy to automatically generate labels for person tracks to learn similarity metric for multi-shot person re-identification task. Specifically, we use the fact that non-matching (negative) pairs far out-number matching (positive) pairs in any training set. Therefore, the true class conditional probability of distance given negative class can be estimated using the empirical marginal distribution of distance. This distribution can be used to sample non-matching person pairs for metric learning. A brief overview of the approach is presented below, please refer to [33] for details.
|
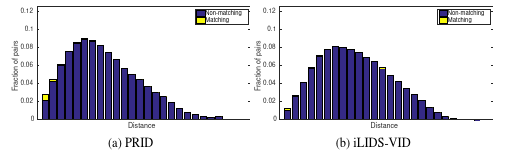
In figure 12, empirical distribution of Euclidean distance (using MCM [43] representation) is plotted for two publicly available datasets. It can be noted that the positive samples lie on one side of distribution mode. Therefore, negative pairs can be sampled according to the probability proportional to the signed distance from the mode. Practically, we only select sample pairs that are farthest away in the distribution as negative pairs. For positive pairs, we use the fact that each track has more than one image for a person. Thus we generate positive pairs using the persons selected for negative pairs. We evaluated our approach on three publicly available datasets in multi-shot settings: iLIDS-VID, PRID and iLIDS-AA. Performance comparison of different representations using recognition rates at rank are detailed in table 12, table 13 and table 14. Our results validate the effectiveness of our approach by considerably reducing the performance gap between fully-supervised models using KISSME algorithm and Euclidean distance.
| Method | r=1 | r=5 | r=10 | r=20 |
| MCM+MPD | 53.6 | 83.1 | 91.0 | 96.9 |
| MCM+UnKISSME | 59.2 | 81.7 | 90.6 | 96.1 |
| MCM+KISSME | 64.3 | 86.1 | 94.5 | 98.0 |